
New Servers, Better Servers: Behind the Scenes with Hathora

Last week, I had the opportunity to sit down with Siddharth Dhulipalla, Co-Founder and CEO of Hathora.dev, Frost Giant's server hosting solution. They've got some pretty interesting tech that RTS fans will be rather excited about. Enjoy!
Thanks so much for joining me today, Sid. Before we get into the nitty gritty, can you give me the bird's-eye view of what Hathora does?
Yeah, absolutely. First off, thanks so much for having me - looking forward to this conversation. I guess, you know, some brief background on Hathora. We provide server hosting for the most ambitious multiplayer games around the world. So, if you're building a real time game where a few milliseconds of latency actually matters to gameplay, you're probably having to host your servers around the world, thinking about how many idle servers you have and in what regions, where you send players, how bad their ping is in each region, that kind of thing. It's a whole set of operational challenges that traditionally studios had to deal with. Hathora solves all of that for you.
So instead of having to maintain a fleet of clusters around the world, you actually send your server build over to Hathora. When you have a pool of players ready to start a match Hathora, spins up compute for you dynamically and assigns a server for that set of players. So we're really hoping to kind of change the gaming industry in terms of how server hosting is done because, frankly speaking, we feel like this is a common problem that every studio has to deal with and it's a very similar solution everyone kind of ends up reinventing. It felt like one of those perfect platforms to provide the studio so that they don't have to worry about that stuff in-house.
How does that make you different from someone like Amazon AWS, or Microsoft Cloud Azure or one of these really well-known hosting platforms?
Yeah, for sure. I mean, this isn't the first time ever that this is being done - this problem has been solved in the past. And in fact, a lot of studios have turned to cloud hosting, picking something like EC2 on AWS or Azure VMs to host their games.
The difference that we see is in terms of how infrastructure as a whole outside of game servers has evolved in the last 20 years. You started with these workstations that sat on people's like desks or in a closet somewhere to moving up to a rack of servers in a closet to that rack of servers being hosted somewhere by a company like Equinix.
And then Virtual Machines started coming around in the early 2000s and that was a next step in the evolution. And then those virtual machines - instead of hosting them on bare metal or metal that you owned, cloud was the transition where Amazon or Azure or Google provide those virtual machines for you.
And then the next leap that we see that took place is basically this transition to containers - and then from containers, what we're actually noticing is it's transitioning to serverless, where it functions more as a service. If you look at the evolution, it's always increasing how much the platform handles for you and decreasing your operational overhead.
And so that's kind of how we see ourselves as like being different from just using a VM on Amazon, for example. If you're using a VM on Amazon, you have to think about which region the VM is running and, and then assigning, players to a specific VM. And then if one isn't enough, which, for most ambitious games like one certainly is not enough, you have to keep track of how many you need - you're always running an excess of servers in anticipation of customer demand so that players don't hit waiting in queues forever. But then once players leave, you also want to downsize those clusters and then you have to repeat that in every region you want that availability in and then you have different attacks that you need to protect against or kernel vulnerabilities where you have to patch your underlying OS.
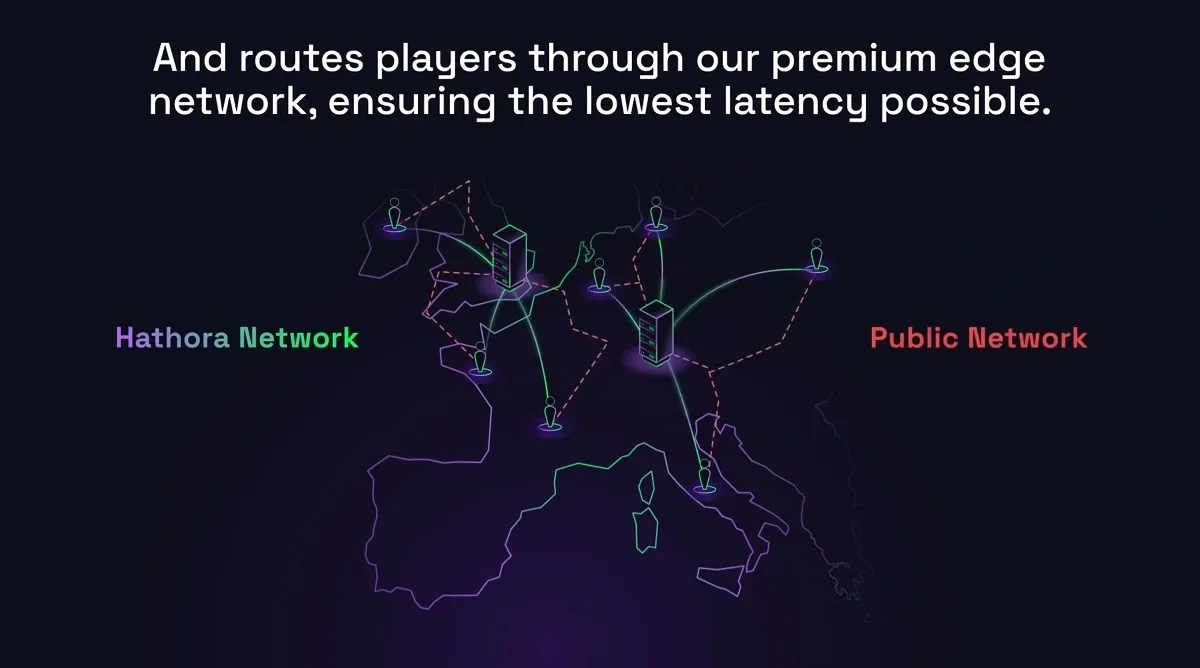
I can go on and on about like all operational challenges that are actually required, even if you're using like a cloud VM versus the difference with us is once you build your server build and containerized it, you throw that server build over to us and then we are entirely responsible for everything below that - the number of active servers that we need in order to schedule all the games that are coming in, patching them so that any critical vulnerabilities are addressed as quickly as possible, protecting games from getting attacks, etc. The other really key important thing is we have servers available in ten regions already that our customers can pick from. So, for example, Fortnite or any other game that's hosted on Hathora has access to a ping checker which they can integrate into their respective clients and test for a given player what is the closest or a region. That gets fed into the matchmaker so that the matchmaker can decide what the optimal region to place these users into is.
Amazon Prime Video recently came out and said it's actually far, far cheaper for them to host on bare metal to have their own server setups than to go into AWS. For Hathora, it seems that you get around that by only spinning up servers exactly when you need to, and no other time. Can you explain what exactly Hathora's value proposition is?
Yeah. So I want to deconstruct that a little. I know which blog post you're referring to and Prime Video - the way things were set up, they were using serverless in a very Frankenstein way. It was a very complex distributed system that they tried to build using serverless techniques where you had one service that was responsible for the intake of videos and then another service that was responsible for encoding it properly and another for serving it up when it needed to. So you needed this very cohesive system, this platform at the end of the day. But then the way it was architected was [that there were] all these individual pieces that were kind of hard to kind of figure out. So the transition they made actually is not wasn't to bare metal. They actually ended up consolidating a few key services into these mini monoliths, so to speak.
All of their ingestion service, for example, was baked into one service and then they deploy that one service on an EC2 instance, instead of having it run and lambda. So it's not that they have said serverless does not work for anyone and it's a bad paradigm - it's just like for their use case, they've actually realized that, instead of reducing operational complexity it increased operational complexity and it didn't actually have cost benefits - it didn't quite make sense for them. In the example or in the use case of game servers, serverless is actually pretty useful because there's not a lot of dependency between - so when you're playing a like game, if it's an unreal engine game or a unity game, there's usually only one thing that you're connected to. And so there's not a lot of distributed systems complexity that comes in. And so when we say serverless, it's actually the fact that we're able to launch your unity or unreal back end server very, very quickly. And then like you said, the huge benefit is that you're paying for exactly the time that it's in use for. So that's the pitch of serverless is that it's not actually - for certain use cases serverless actually helps tremendously, but I think it has gone too far in some dimensions to kind of make it worse. So it does that.
You mentioned that you're in ten regions. Of course, more are on the way, but when you look at these ten regions, are we looking at if you look at kind of the infrastructure, are we looking at these ten regions as US East, US Central, US West, etc. where effectively each node is going to be architected to be its own subregion or is this something where you have all these regions and it really doesn't matter where it is - its just a centralizing tool?

I think what you're trying to get at is like, what is the purpose of a region, right? Is it meant to reduce latency for all involved players? Is it meant for a distributed load or what's the advantage with more regions essentially?
Yeah, and how interconnected are these nodes or how interconnected are these nodes designed to be? Because clearly any individual game can do what they want in terms of how to localize things.
Yeah, absolutely. From our perspective, each region is isolated. The advantage that you got from that is actually high resiliency. For example, let's say some of our providers are having an outage in one region. None of the games in the other regions will be affected. And in fact, we can actually reroute games that are requested for a certain region to another region, if there's an internet outage or bad weather occurring around that zone. So the thing is like ultimately each game server that a studio provides us kind of runs in an isolated fashion. They tell us what region that we should schedule it in - for example, if you have a player in Poland and a player in Seattle, you could say, "I'm going to pick the region that the first player that joined whatever region is close to them." For us, if the Poland player joined, the closest region would be Frankfurt. Anyone that joins after just has to deal with additional latency and join the Poland server. That's one approach you can take.
The other more common approach that we tend to see is to, while people are still in matchmaking, identify what's the best average latency for both players. So for someone in Poland and for someone in Seattle, probably our D.C. server region would be the best. Ultimately it's up to the matchmaker to tell us what region they want the game scheduled in and we give them the tools that are needed to assess pings to the various server regions that we have. But we don't want to be prescriptive about gameplay logic. Maybe a studio does prefer one over the other and we want to leave it up to the studio.
So it's not quite the AOE 4 approach - where they use Microsoft Cloud Azure to find the mini server that is as ping-neutral as possible. Hathora is not quite there, where you do have more localized, more centralized clusters or nodes that you're going to be connecting to rather than what is the most optimal ping or a ping centralized location, correct?
Yeah, absolutely. And what we've noticed, is that if you go too small or too granular, especially for like games that are kind of like just coming online, there's not enough of a player base to support enough capacity or there's not enough players in a given local zone. So like let's say you pick Dallas - Dallas might only have a subset of players and the pool isn't large enough to make it worthwhile to have a Dallas server. So again, this is one of those things where like as we get larger and we start onboarding a lot more games, it probably makes sense for us to start spinning up more and more regions.
But for now, our primary goal is to have a region within 40 milliseconds from 90% of the world's players. And I think I have to caveat that by saying like excluding China, because, you know, China is a beast in and of itself.
So do you all do you own all of your server hardware then, or is this built on AWS or Google Cloud Services or Azure or something like that?
Yeah, so we actually use a mix of hardware providers and we've done a lot of evaluation in terms of compute performance and consistency. All of the servers that we are hosting around the world have roughly the same hardware profile. And then the other thing that we've invested heavily in is actually network benchmarking.
We ensure that the vendors that we've chosen have direct connections to the major Internet exchanges so that you're not hopping too many times before you end up at the game server, which greatly reduces latency but also reduces dropped packets and jitter as well, which is ultimately what matters tremendously for a good gameplay experience.
Talking about how you actually the service works a little bit, how in-depth or how interconnected is the client, Frost Giant in this case? Is there some sort of custom slug like Heroku that you put on it, or are you just providing a VM that Frost Giant logs in to deploy their system onto?
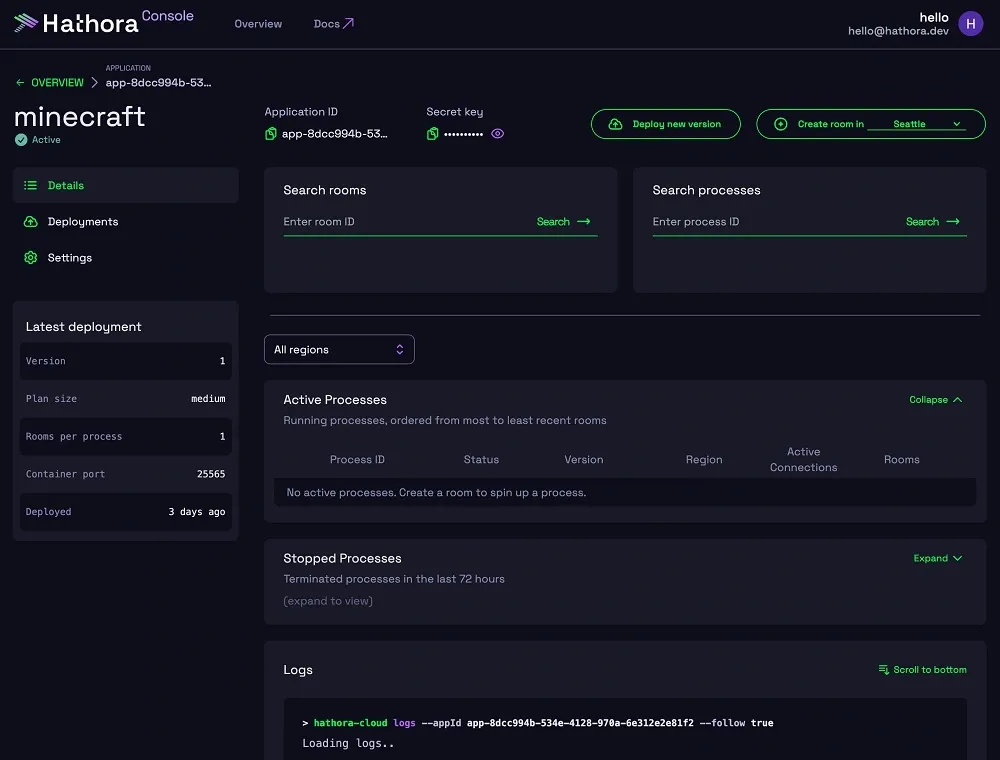
Our platform is actually self-service. In fact, you can log into our platform - we actually kind of walk you through setting up a Minecraft server. So if you have a Minecraft client, you could actually just log into our console, deploy a Minecraft server, connect to it, and it kind of just get a feel for what the platform actually provides. We're very much an API first company. We care a lot about developer experience and even for some unreal engine games the time to onboard some customers has been under 30 minutes. So early on you earlier you were asking about you know what is the value proposition for serverless - whats the main value? I would actually say the time to onboarding is the bigger value proposition, in that most studios can do this in-house if they really put their mind to it but you're probably talking about a team of like 3 to 5 engineers at the very least to build out the thing.
And then even once it's built out, you probably want one or two engineers just babysitting and monitoring these global fleet of servers at any given time. That's a huge piece of the problem that we're taking away from studios that are building their game. And then on top of that, it's just this performance angle as well where, even if you hire a team in-house, can you actually spend as much time as we spend evaluating these vendors, benchmarking them the way we have, deciding which regions are key? This is our bread and butter. This is ultimately like what makes or breaks our company versus, for a lot of game CEOs, this is a secondary or a tertiary concern because ultimately they care about things like gameplay and unit movement and whether the game overall fun to play. For them, server hosting just has to be good enough. For us, we want it to be the best. That's kind of the bigger difference that we see.
Hathora is specifically looking at supporting multiplayer games. Outside of the low latency and easy deployment, is there anything that makes Hathora especially suited to hosting multiplayer games vs hosting an eCommerce site, for example?
That's a great question. So when we first got started - both me and my co-founder, we come from a decade of infrastructure experience and we saw this evolution that I was referring to earlier from bare metal to virtual machines to containers to serverless. And we're like, "Well, what's happening in the gaming world and, more, more comprehensively, what's happening in the stateful services world?" I'll make a pretty clear, technical demarcation. When you're interacting with a service like Facebook or any web app that you've interacted with, generally those are stateless applications. Your browser sends a cookie with every request that the server then uses to populate the entire state of your profile from a database. The web server itself is keeping nothing in memory. Everything, all the persistence is in a database layer somewhere beneath it. Scalability becomes a lot simpler. You throw a load balancer in between, and then it could go to any one of N web servers and it's fine.
For games, that just does not work. And, more broadly for stateful applications, that doesn't work. Stateful operations are where you have a lot of computation that's happening in memory where you can't wait to persist a ton of data to a database and read it on the next tick and then do what you need to and then write it back and do that for every player. It's just too computationally intensive, it leads to a lot of additional latency as well. And so the way games work, even on the server side, everything's running in memory. For example, if you have ten players that are playing the same game session, you can't have a load balancer in front of them and send them to ten different servers - they need to be physically connected to the same process. All of the architectural improvements that the Enterprise SAS side has seen over the last decade, very little is transferable to the gaming industry. But the thing is that there's nothing preventing it - there's no fundamental rule or physical limitation that says it cannot be done. There just hasn't been enough investment on this side.
And so to answer your question, we see gaming as a really, really good starting point for us. And it's kind of like the most extreme version of the problem that we're solving for. But actually, if you look at it, if you're hopping into an Uber ride - the driver and you and Uber all need to be on the same page. It's sort of a multiplayer experience. Same deal if you're editing a figma document - it's very similar to like how a multiplayer game is hosted. I think at some point in the future we kind of see a world beyond gaming, but we think that gaming is the hardest version of this problem and the most performance sensitive, latency sensitive problem problem that we can solve. So if we get it right here, we feel like expanding beyond is not difficult, but gaming is our absolute focus right now.
I do want to go back to the kind of this ping distribution thing that we talked about as we kind of get towards the end of things here. One of the topics that has been entering gaming discourse recently has been this concept of players blocking servers they aren't a fan of or using a VPN to spoof location to get better servers for them. Have you given any thought to how to deal with that or does Hathora provide any protection there?
Yeah, I mean, that's a that's a very, very difficult problem to solve, and there's multiple layers. I don't know - I don't have a great response because from a technical perspective, it's not easy to identify when this occurs. So then it becomes one of those things where you can identify it after it occurs and then maybe ban the player or kind of, you know, treat them differently. But it's very challenging because there's a chance that what actually happened was that the player had a network blip and they disconnected from their Wi-Fi and had to like go plug in into their Ethernet. And then they saw the same kind of latency improvement as like someone else disconnecting from a VPN to force added latency. It becomes up to the game to decide how to handle some of these. We provide the tooling to help them and provide them with the data. But we don't want to be prescriptive in terms of how to handle certain behaviors.
So you provide the tools to detect something is happening, but don't do any decision making on how to handle it, if I'm getting that right?
Yeah. The ping checker tool that we provide is what I'm referring to here. Our customers generally use the ping checker tool when the client is launching for the first time. And so then they reach out to all of our servers, and it comes back saying, "Hey, you're closest to X, Y and Z, and here's the ping to the rest of it." If that changes drastically in the middle of the game or right as the game session is about to begin, I think you could reasonably argue that it's likely that it's because they hopped off a VPN. It's one of those things where if they actually switched from Wi-Fi to Ethernet - same problem. But the thing is, at least in that case, the distribution is going to remain the same or the sorted ordering is going to remain the same. So that order is like, you go from London being the closest to suddenly like Singapore being the closest. It's pretty hard to explain why that could be the case without you hopping through some VPN node somewhere. But again, understanding and analyzing this behavior is not something that we're putting a lot of thought into right now.
Before we're done here, is there anything that you're excited about, about Hathora or how Hathora is merging with Frost Giant that I haven't asked about that you want to talk about?
Yeah. We've been working with Frost Giant for about six months now. The game is coming along really, really nicely. The reveal yesterday was just exciting to see some public material that we can point to as well. The team is amazing. We're really, really looking forward to seeing how the game does. And yeah, and I think for us personally, we go like far beyond just one genre or one platform. Hathora is cross game engine. We support Unity, Unreal, Godot, and any JavaScript stuff as well. And we're also cross-platform. We can work with PC, console, VR as well. And yeah, any game type as well (RTS, MOBA's) - as long as they're session based, we're excited to work with them.
Two final questions for you. One, if you can't answer this, that is totally fine. But we know some players have been playing games remotely on testing. Is that because Frost Giant has deployed to Hathora at this point, or are we still waiting on that?
I know the answer, but, you know, I'd prefer Gerald or someone from the project team answering!
Fair enough - just figured I'd ask! And then final thought, if people are interested in finding out more about you or Hathora or we do have the Hathora dev twitter account link down below, we have your personal LinkedIn, but anything else they should take a look at if they want to find out more?
Yeah. Our Discord community is very active, so Discord.gg/Hathora and then you know we have some very comprehensive docs and our landing page at Hathora.dev is a great starting point as well.
About Siddharth
Siddharth Dhulipalla is the Co-Founder and CEO of Hathora.dev, a novel server hosting solution for online multiplayer games. You can follow him on LinkedIn at https://www.linkedin.com/in/dsiddharth/ and check out Hathora's twitter at https://twitter.com/HathoraDev.
How to Get Involved
As always, if you want to engage with the Frost Giant developers and get information from them as they post it, you should sign up for their newsletter, head on over to /r/Stormgate on reddit, and sign up for the beta and wishlist the game on steam!